Overview
+?: A B Tree that stores data entries in leaves only- Clustered index to give performance hint.
- Perfectly balanced: every leaf node is at the same depth in the tree
d: The order of a B+ Tree- d ⇐
#entries⇐ 2d (except for the root node) - max
fan-out: `2d + 1 - There are at least two children in the root.
- d ⇐
- All leaves are at the same depth and have between d and 2d entries (i.e., at least half full)
- The entries within each node must be sorted
d=2: 20, nodes;d=3: 500 nodes- Typical order: 1600
- Typical fill rate: 67%
- Total capacity:
Insertion
- Have enough space
- Find the right leaf.
- Perform Sort in the leaf.
- Do not have enough space
- Split leaf if there is not enough room
- Redistribute entries evenly (d entries in left and entries in right)
- Fix next/prev pointers
- Copy up from leaf the middle key (Left most key in right leaf)
- If no room in parent
- Recursively split index nodes
- Redistribute the rightmost d keys to make them split evenly
- Push up middle key (Left most in index node)
- Sort
- Notice that the leaf key is copied (or we lose data), but the index key is pushed (we can still track)
- Notice that the root was split to increase the height
- Grow from the root not the leaves
- All paths from root to leaves are equal lengths
Bulk Loading (Inserting)
Only happens on B+-Tree creation.
Indexes built from bulk loading always start off clustered because the underlying data is sorted on the key
Do not insert key one by one, instead, insert node and link them through navigation node.
Deletion
- To delete a value, just find the appropriate leaf and delete the unwanted value from that leaf
- Reminder: We never delete inner node keys because they are only there for search and not to hold data.
Storing Data
- Method 1: Leaf pages contain the records themselves.
- Method 2: the leaf pages hold pointers to the corresponding records.
- Method 3: the leaf pages hold lists of pointers to the corresponding records. This is more compact than Alternative 2 when there are multiple records with the same leaf node entry.
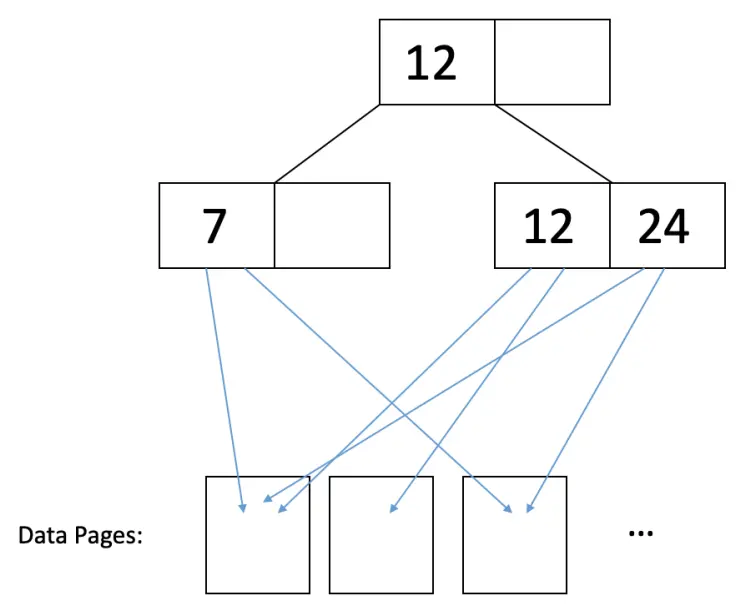
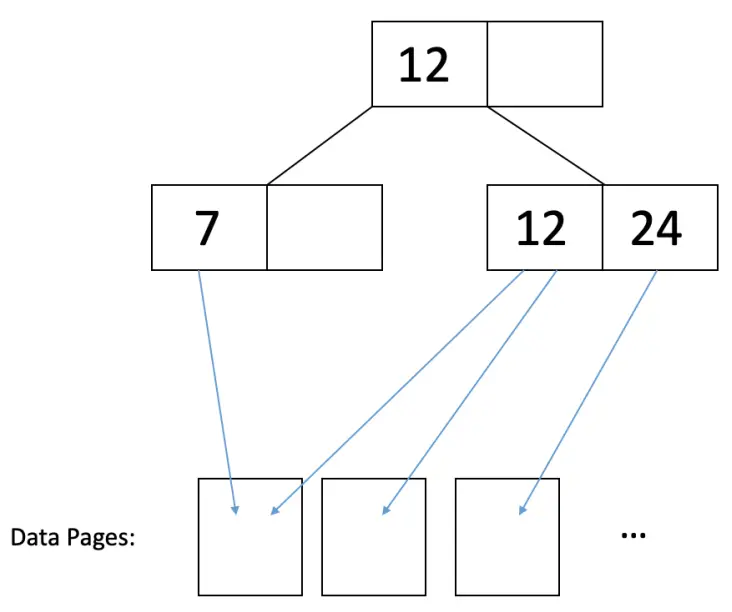
Clustering (How data on the data pages are organized)
Clustered and unclustered indexes refer to how data pages are structured in a B+ tree. In a clustered index, the data pages are sorted on the same index on which the B+ tree is built, while in an unclustered index, the data pages are not sorted. Clustered indexes can be more efficient for range searches and offer potential locality benefits during sequential disk access and prefetching, but they are usually more expensive to maintain than unclustered indexes