Models
Iterator Model
AKA. Volcano or Pipeline model.
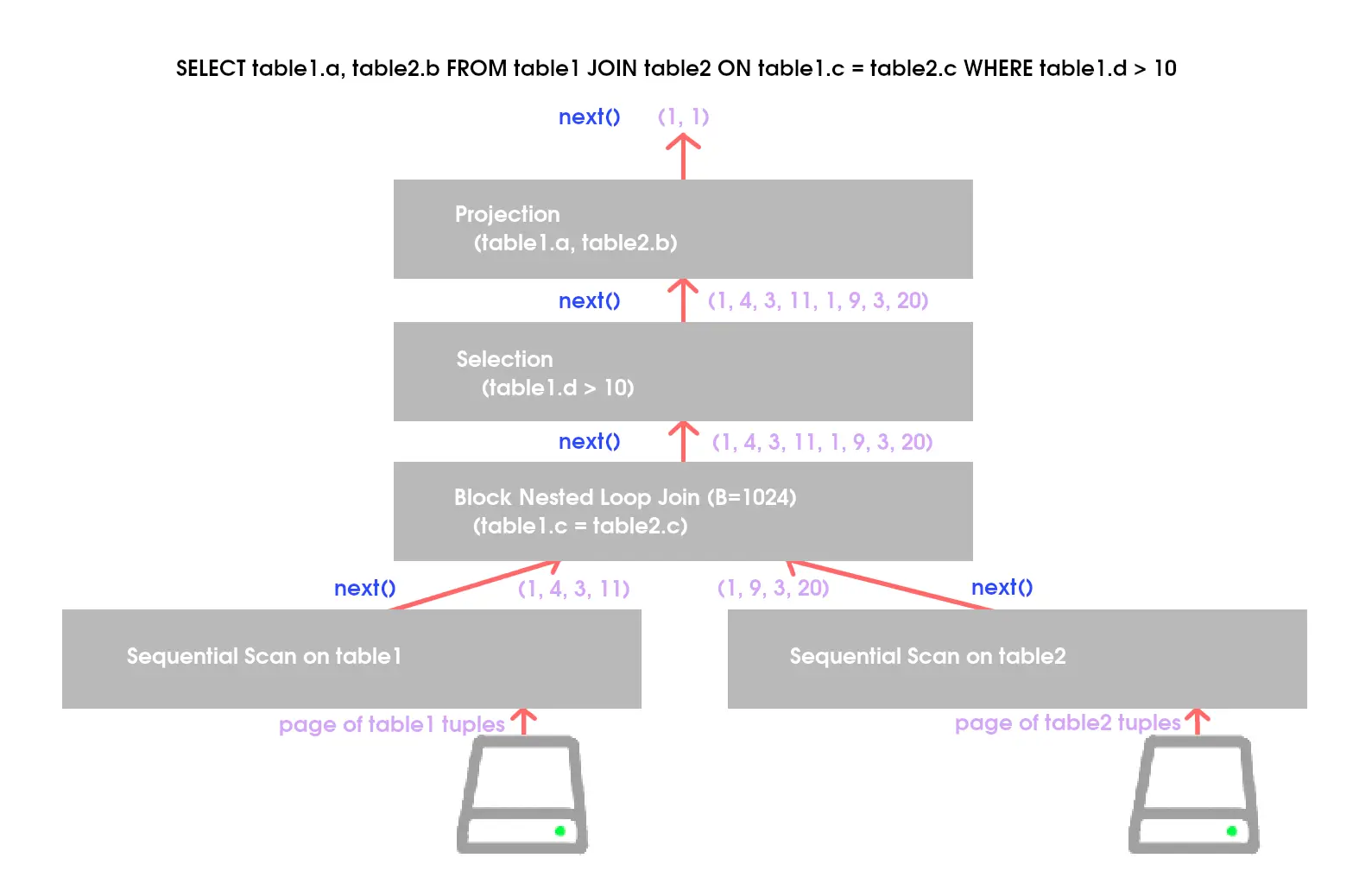
- On each call to Next, the operator returns either a single tuple or a null marker if there are no more tuples to emit.
- The operator implements a loop that calls Next on its children to retrieve their tuples and then process them. In this way, calling Next on a parent calls Next on its children. In response, the child node will return the next tuple that the parent must process.
Materialization Model
Idea: avoid scanning too many tuples.
- The operator processes all the tuples from its children at once. (“materializes” its output as a single result.)
- The return result of this function is all the tuples that operator will ever emit. When the operator finishes executing, the DBMS never needs to return to it to retrieve more data.
Vectorization Model
Idea: combine materialization and iterator model
- each operator emits a batch (i.e. vector) of data instead of a single tuple
- The vectorization model allows operators to more easily use vectorized (SIMD) instructions to process batches of tuples.
Access Methods
Sequential Scan
- Optimization:
- Prefetching: Fetch the next few pages in advance so that the DBMS does not have to block on storage I/O when accessing each page.
- Buffer Pool Bypass: The scan operator stores pages that it fetches from disk in its local memory instead of the buffer pool in order to avoid sequential flooding.
- Parallelization: Execute the scan using multiple threads/processes in parallel.
- Late Materialization: DSM DBMSs can delay stitching together tuples until the upper parts of the query plan. This allows each operator to pass the minimal amount of information needed to the next operator (e.g. record ID, offset to record in column). This is only useful in column-store systems.
- Heap Clustering: Tuples are stored in the heap pages using an order specified by a clustering index.
- Approximate Queries (Lossy Data Skipping): Execute queries on a sampled subset of the entire table to produce approximate results. This is typically done for computing aggregations in a scenario that allow a low error to produce a nearly accurate answer.
- Zone Map (Lossless Data Skipping): Pre-compute aggregations for each tuple attribute in a page. The DBMS can then decide whether it needs to access a page by checking its Zone Map first. The Zone Maps for each page are stored in separate pages and there are typically multiple entries in each Zone Map page. Thus, it is possible to reduce the total number of pages examined in a sequential scan. Zone maps are particularly valuable in the cloud database systems where data transfer over a network incurs a bigger cost. See Figure 4 for an example of a Zone Map.
Index Scan
Idea: Use low selectivity index to speed up scan
Parallelism
Inter Query Parallelism
DBMS executes different queries concurrently
Intra Query Parallelism
DBMS executes the operations of a single query in parallel. This decreases latency for long-running queries.
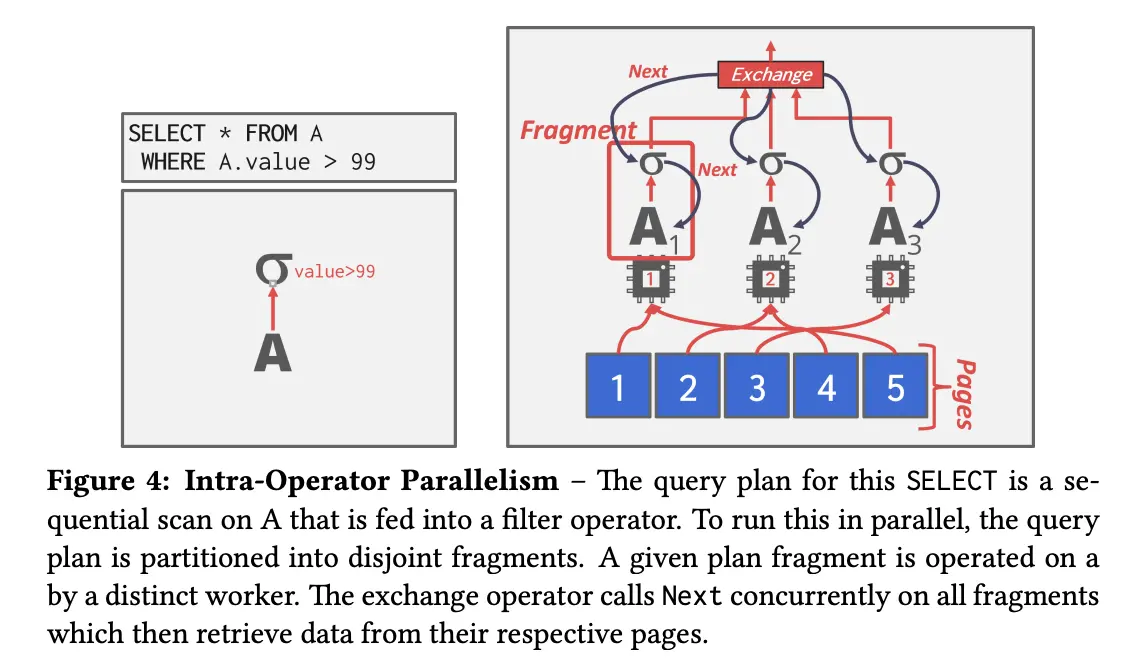
- intra operator (horizontal)
- the query plan’s operators are decomposed into independent fragments that perform the same function on different (disjoint) subsets of data.
- DBMS inserts an exchange operator into the query plan to coalesce results from child operators. The exchange operator prevents the DBMS from executing operators above it in the plan until it receives all of the data from the children
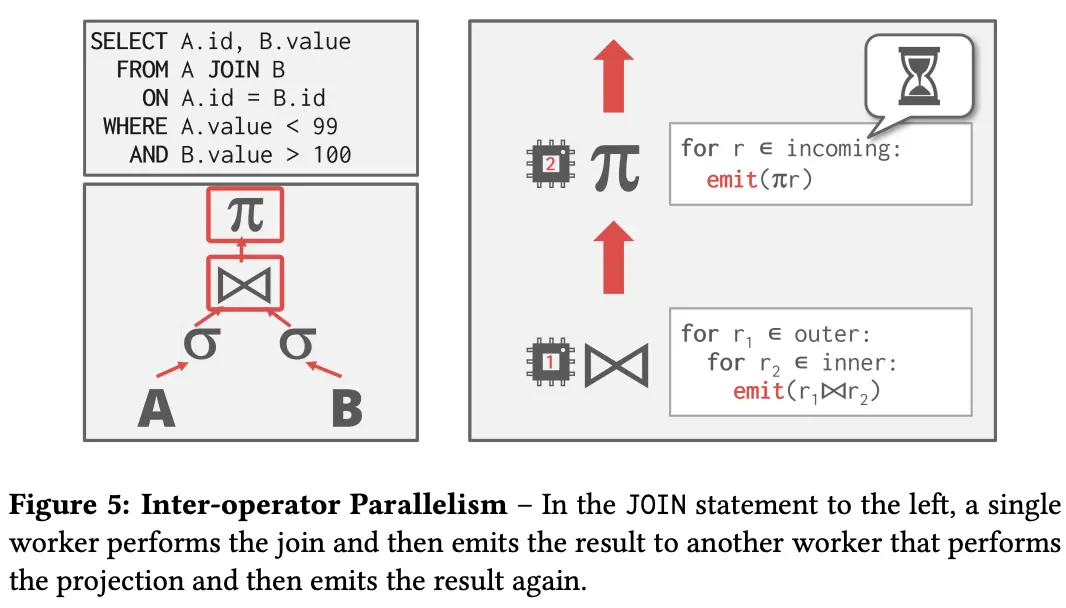
- inter operator (pipelined parallelism)
- DBMS overlaps operators in order to pipeline data from one stage to the next without materialization.
- bushy parallelism
IO Parallelism
Multi-Disk Parallelism
OS/hardware is configured to store the DBMS’s files across multiple storage devices. This can be done through storage appliances or RAID configuration.
All of the storage setup is transparent to the DBMS so workers cannot operate on different devices because the DBMS is unaware of the underlying parallelism.
Database Partitioning
the database is split up into disjoint subsets that can be assigned to discrete disks.