Overview
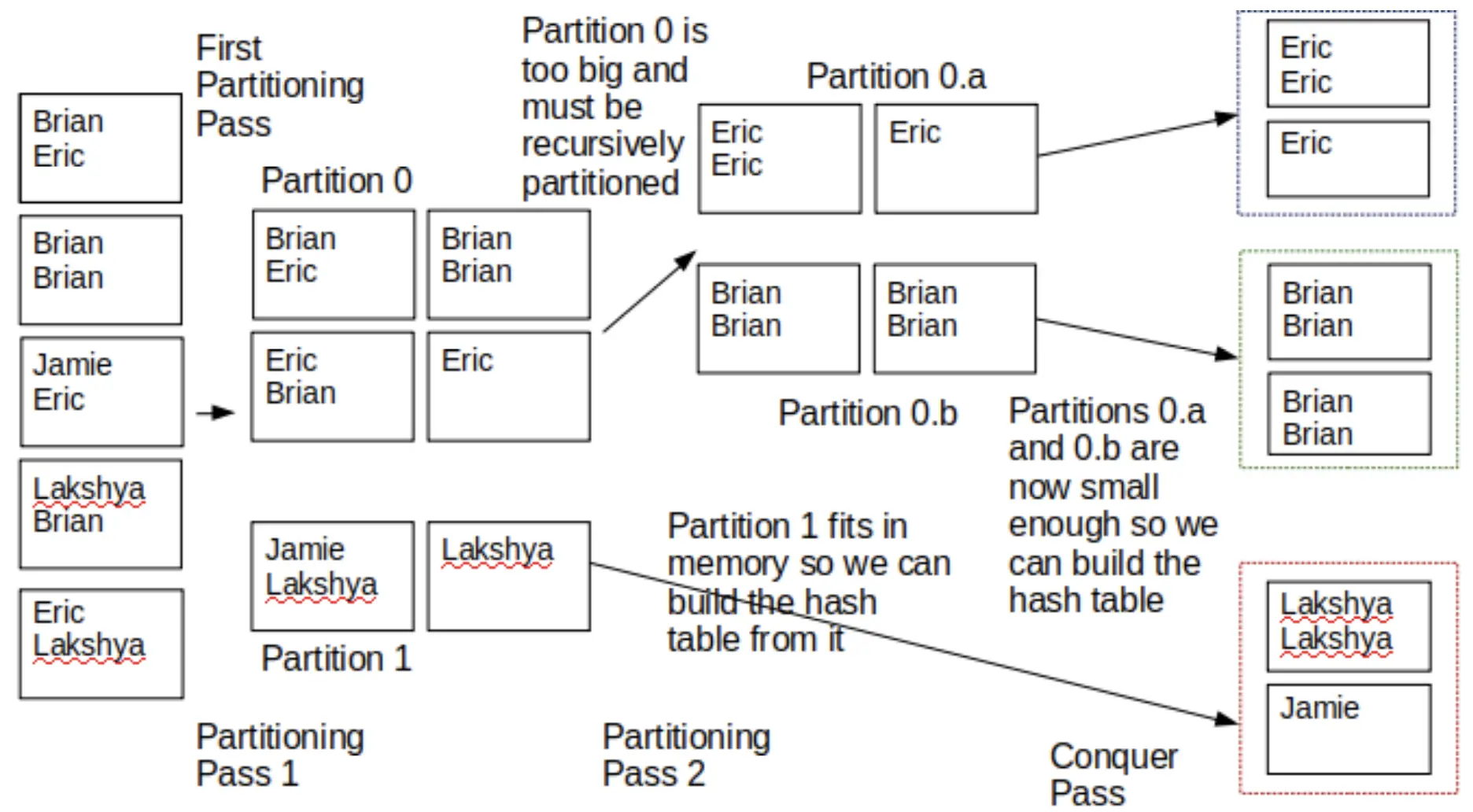
Because we cannot fit all of the data in memory at once, we’ll need to build several different hash tables and concatenate them together.
How to
- Divide and Conquer algorithm to partition and hash
We have buffers, hash each record to partitions. A partition is a set of pages such that for a particular hash function, the values on the pages all hash to the same hash value. We need save 1 buffer for the input buffer.
When output buffer filled, flush it to disk. The two pages that came from the same buffer will be placed adjacently. The most important property of each partition is that if a certain value appears in that partition, all occurrences of that value in our data appear in that partition.