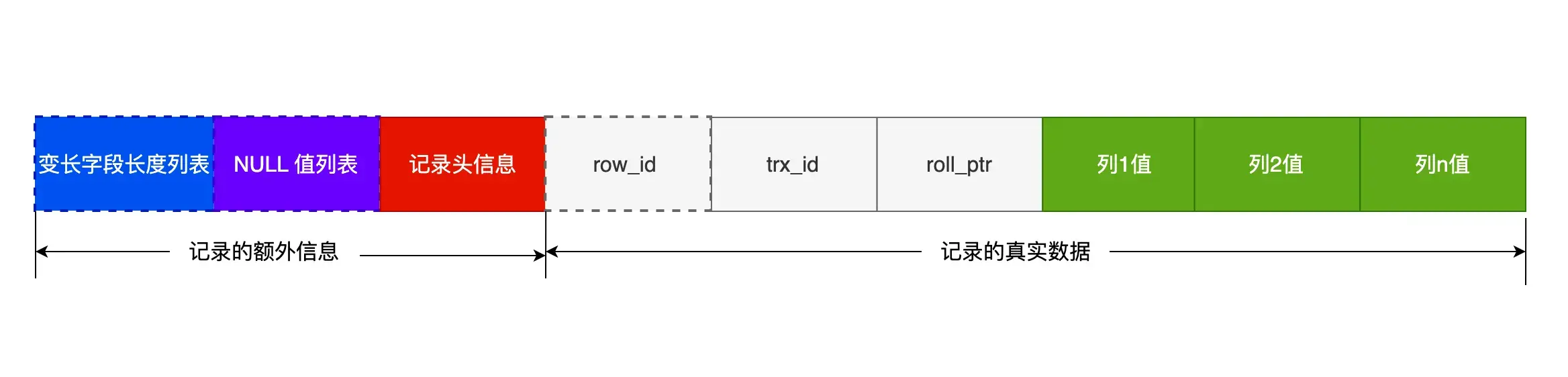
COMPACT 行格式
隔离级别
- 对于「读提交」和「可重复读」隔离级别的事务来说,它们是通过 Read View 来实现的,它们的区别在于创建 Read View 的时机不同,可以把 Read View 理解成一个数据快照。
- 「读提交」隔离级别是在「每个语句执行前」都会重新生成一个 Read View
- 「可重复读」隔离级别是「启动事务时」生成一个 Read View,然后整个事务期间都在用这个 Read View。
这两种开启事务的命令,事务的启动时机是不同的:
- 第一种:begin/start transaction 命令;
- 执行了 begin/start transaction 命令后,并不代表事务启动了。只有在执行这个命令后,执行了第一条 select 语句,才是事务真正启动的时机;
- 第二种:start transaction with consistent snapshot 命令;
- 执行了 start transaction with consistent snapshot 命令,就会马上启动事务。
索引
主键索引的 B+Tree 和二级索引的 B+Tree 区别如下:
- 主键索引的 B+Tree 的叶子节点存放的是实际数据,所有完整的用户记录都存放在主键索引的 B+Tree 的叶子节点里;
- 二级索引的 B+Tree 的叶子节点存放的是主键值,而不是实际数据。
- 这种在二级索引的 B+Tree 就能查询到结果的过程就叫作「覆盖索引」,也就是只需要查一个 B+Tree 就能找到数据。
- 覆盖索引是指 SQL 中 query 的所有字段,在索引 B+Tree 的叶子节点上都能找得到的那些索引,从二级索引中查询得到记录,而不需要通过聚簇索引查询获得,可以避免回表的操作。
联合索引的最左匹配原则,在遇到范围查询(如 >、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段的后面的字段无法用到联合索引。注意,对于 >=、⇐、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配,前面我也用了四个例子说明了。
聚簇索引 Clusterd Index
- 物理存储:聚簇索引决定了表中数据的物理存储顺序。一个表只能有一个聚簇索引,因为你不能以两种不同的方式物理存储同一份数据。
- 特点:由于聚簇索引决定了数据的物理排列方式,所以它能够快速地访问连续的数据。当通过聚簇索引进行查询时,能够更快地找到数据,尤其是在进行范围查询时效果最佳。
- 性能:插入、删除操作可能会导致数据的物理重新排列,影响性能。
非聚簇索引
- 物理存储:非聚簇索引与数据的物理存储顺序无关。一个表可以有多个非聚簇索引。
- 特点:非聚簇索引存储的是索引字段和指向表中数据行的指针,而不是数据本身。这意味着使用非聚簇索引查找数据时,数据库首先找到索引中的条目,然后再通过指针找到数据所在的位置。
- 性能:非聚簇索引一般来说读取速度比聚簇索引慢,因为它需要两次访问:一次是访问索引,一次是通过索引中的指针访问实际的数据行。但是,对于插入和删除操作,非聚簇索引的性能影响小于聚簇索引,因为它不需要对数据本身进行物理重排。
锁
表级锁
MDL 锁
- 对一张表进行 CRUD 操作时,加的是 MDL 读锁;
- 对一张表做结构变更操作的时候,加的是 MDL 写锁;
意向锁
- 在使用 InnoDB 引擎的表里对某些记录加上「共享锁」之前,需要先在表级别加上一个「意向共享锁」;
- 在使用 InnoDB 引擎的表里对某些纪录加上「独占锁」之前,需要先在表级别加上一个「意向独占锁」;
- 意向共享锁和意向独占锁是表级锁,不会和行级的共享锁和独占锁发生冲突,而且意向锁之间也不会发生冲突,只会和共享表锁(lock tables … read)和独占表锁(lock tables … write)发生冲突。
如果没有「意向锁」,那么加「独占表锁」时,就需要遍历表里所有记录,查看是否有记录存在独占锁,这样效率会很慢。
那么有了「意向锁」,由于在对记录加独占锁前,先会加上表级别的意向独占锁,那么在加「独占表锁」时,直接查该表是否有意向独占锁,如果有就意味着表里已经有记录被加了独占锁,这样就不用去遍历表里的记录。
意向锁的目的是为了快速判断表里是否有记录被加锁
Binlog
用于记录所有对数据库执行更改操作(包括 DDL 和 DML)的日志文件。它记录了数据的更改事件,而不是查询本身
Explain
1. system
- 描述:表只有一行记录(等于系统表)。
- 特性:这是
const类型的特例,通常不会出现,可以忽略。
2. const
- 描述:通过索引一次就找到匹配行。
- 适用:用于比较主键(Primary Key)或唯一索引(Unique Index)。
- 特点:因只需匹配一行数据,查询速度极快。如果在
WHERE列表中涉及主键,MySQL 可将该查询转换为const。
3. eq_ref
- 描述:唯一性索引扫描。
- 适用:每个索引键仅匹配表中的一条记录。
- 特点:常见于主键或唯一索引扫描。
4. ref
- 描述:非唯一性索引扫描。
- 适用:返回匹配某个单独值的所有行。
- 特点:
- 结合了查找与扫描的特性。
- 可能匹配多行,效率次于
eq_ref。
5. range
- 描述:检索给定范围内的行。
- 适用:在
WHERE语句中包含BETWEEN、<、>、IN等条件。 - 特点:
- 利用索引列上的范围扫描。
- 比全索引扫描效率更高。
- 从某个点开始到另一点结束,无需扫描整个索引。
6. index
- 描述:全索引扫描(Full Index Scan)。
- 适用:遍历整个索引树。
- 特点:
- 与
ALL的区别在于index只读取索引,ALL则直接从硬盘读取数据。 - 因索引文件通常比数据文件小,效率略高于
ALL。
- 与
7. ALL
- 描述:全表扫描(Full Table Scan)。
- 特点:
- 遍历整张表以找到匹配行。
- 最低效的查询方式。
注意
- 对于
ALL,选择表记录最少的表(如t1)以降低查询开销。